
Time-series data powers everything from financial trading platforms and IoT sensors to infrastructure monitoring and user analytics. While Timescale has become a well-known extension of PostgreSQL for handling time-series workloads, it’s far from the only option. Developers today have a rich ecosystem of specialized databases and analytics engines that offer different architectures, scaling models, and performance optimizations tailored to specific use cases.
TLDR: Many developers turn to alternatives like InfluxDB, ClickHouse, Prometheus, Apache Druid, and OpenTSDB instead of Timescale for time-series analytics. These solutions offer advantages such as horizontal scalability, lower-latency ingestion, columnar storage performance, and purpose-built monitoring features. The right choice depends on workload type, query complexity, operational preferences, and scalability requirements. Each tool brings its own trade-offs in performance, ecosystem maturity, and operational complexity.
Below, we’ll explore some of the most popular solutions developers use instead of Timescale, why they choose them, and how they compare.
Why Developers Look Beyond Timescale
Before diving into alternatives, it’s important to understand why teams sometimes seek other options. Common reasons include:
- Massive horizontal scalability needs beyond a single PostgreSQL-based architecture
- Ultra-high ingestion rates (millions of events per second)
- Real-time analytics with sub-second latency
- Fully managed cloud-native solutions with minimal operational overhead
- Columnar storage optimization for analytical queries
In many scenarios, developers aren’t replacing Timescale because it’s inadequate—they simply need a different design philosophy.
1. InfluxDB
InfluxDB is one of the most established purpose-built time-series databases. Unlike Timescale, which extends relational PostgreSQL, InfluxDB is built from the ground up specifically for time-stamped data.
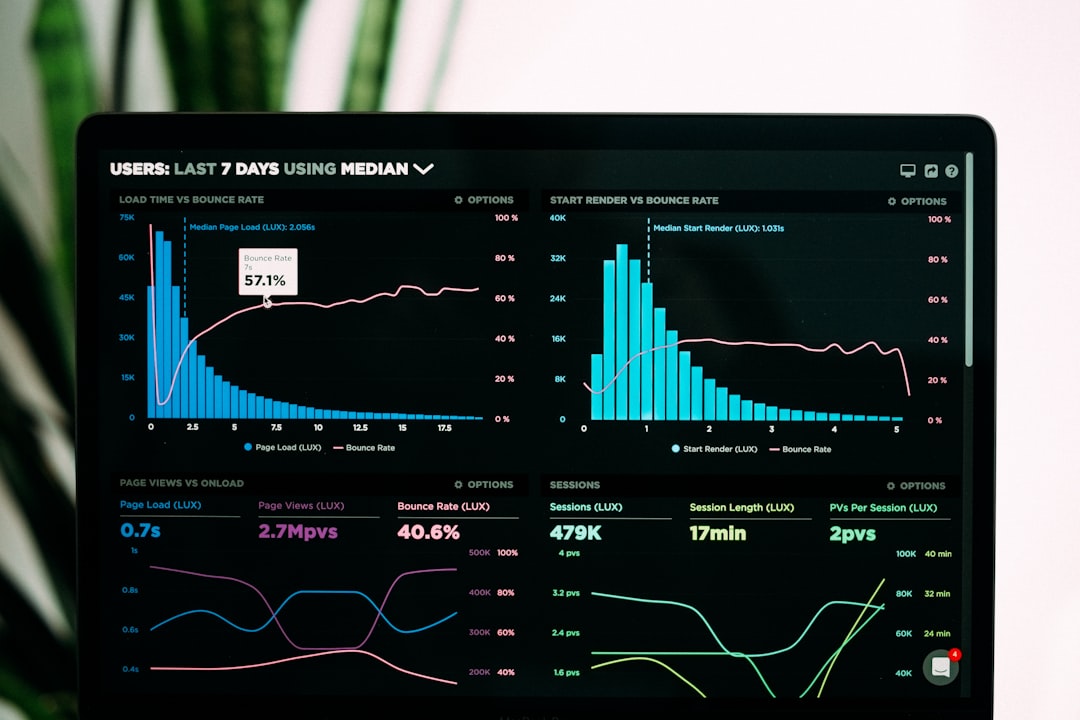
Why developers choose InfluxDB:
- Optimized storage engine designed for high write throughput
- Native time-series compression
- Powerful querying with Flux language
- Strong ecosystem for DevOps and IoT applications
InfluxDB excels in environments such as:
- Infrastructure monitoring
- IoT telemetry
- Application performance monitoring
Its purpose-built engine often results in simpler configuration compared to modifying a relational database for time-series workloads.
2. ClickHouse
ClickHouse is a columnar database management system designed for online analytical processing (OLAP). Although not strictly a time-series database, it handles time-stamped data extremely well.
Why developers prefer ClickHouse:
- Column-oriented storage for faster analytical queries
- Exceptional performance on large datasets
- Built-in horizontal scaling
- High compression ratios
ClickHouse shines in scenarios with:
- Real-time event analytics
- Ad tech metrics
- Financial trading analytics
- Behavioral tracking at scale
For teams processing billions of events daily, ClickHouse can outperform traditional relational systems due to its columnar architecture and distributed query execution.
3. Prometheus
Prometheus is widely used for monitoring and alerting in cloud-native environments. While it isn’t a general-purpose time-series database like Timescale, it’s often the default choice for Kubernetes and microservices observability.
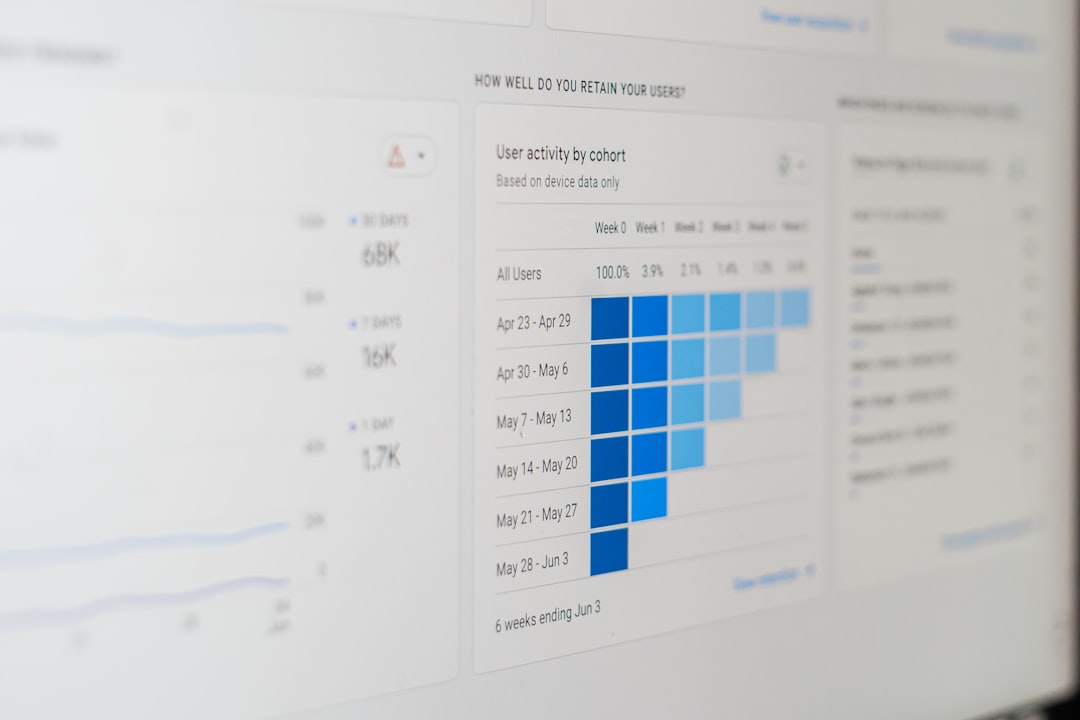
What makes Prometheus attractive:
- Pull-based metrics collection model
- Built-in alerting rules
- Tight Kubernetes integration
- Powerful PromQL query language
Prometheus is ideal when:
- You need operational monitoring rather than historical analysis
- You’re managing containerized infrastructure
- Low-latency alerting is critical
However, it’s typically not used for long-term storage of massive historical datasets without additional tools like Thanos or Cortex.
4. Apache Druid
Apache Druid is a high-performance, real-time analytics database designed for fast slice-and-dice queries on large datasets.
Why developers choose Druid:
- Real-time ingestion and querying
- Optimized indexing for time-based queries
- Distributed architecture
- Sub-second response times for complex aggregations
Druid is commonly used for:
- User-facing analytics dashboards
- Product analytics platforms
- Operational business intelligence
Its segmented architecture separates ingestion from query processing, enabling consistent performance under heavy workloads.
5. OpenTSDB
OpenTSDB is an older but still relevant time-series database built on top of Apache HBase. It’s particularly useful in large distributed environments.
Strengths of OpenTSDB:
- Built for scale via HBase and Hadoop ecosystems
- Handles billions of data points
- Strong in distributed systems environments
OpenTSDB tends to appear in enterprises already running Hadoop infrastructure. While it requires more operational complexity, it can handle extremely large time-series datasets across clustered environments.
6. Elasticsearch
Elasticsearch is often used for log and event data that includes timestamps. While not purely a time-series database, it provides strong search and aggregation capabilities over time-based data.
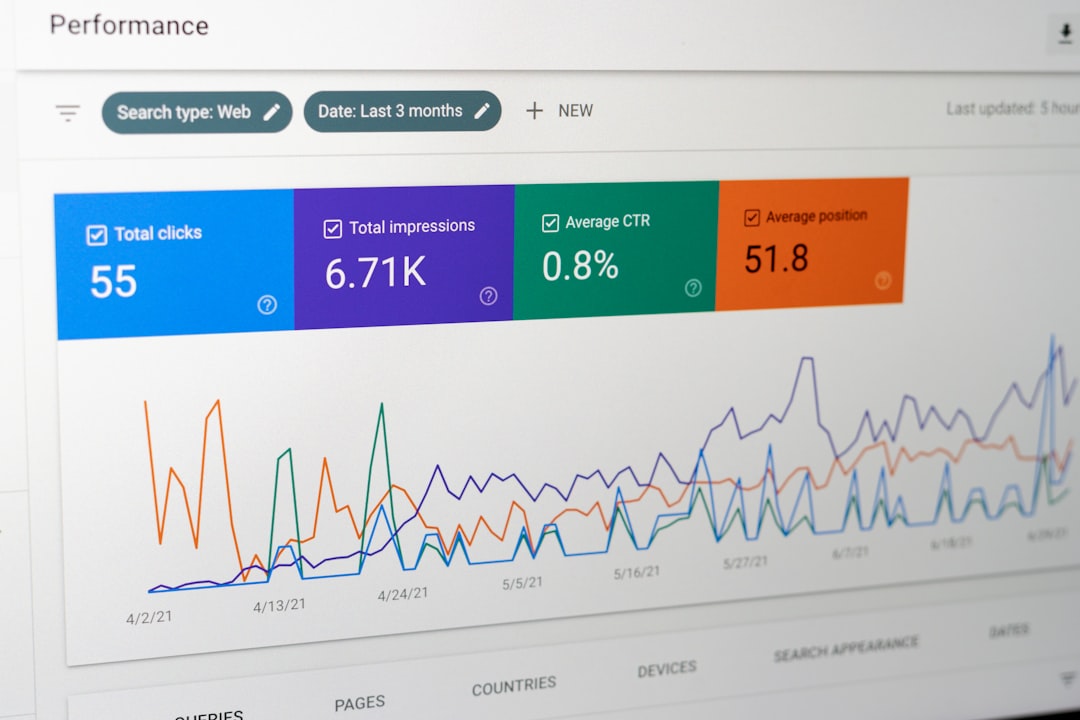
Why some teams use Elasticsearch instead of Timescale:
- Full-text search capabilities
- Strong log analytics tooling (ELK stack)
- Scalable distributed architecture
- Near real-time indexing
Elasticsearch works particularly well for:
- Log aggregation
- Security event analysis
- Application troubleshooting
If querying involves both text search and time filtering, Elasticsearch can be a pragmatic choice.
Comparison Chart
| Solution | Best For | Architecture | Scalability | Query Strength |
|---|---|---|---|---|
| InfluxDB | IoT, DevOps monitoring | Purpose-built time-series | High | Strong time-based queries |
| ClickHouse | Large-scale analytics | Columnar OLAP | Very High | Fast aggregations |
| Prometheus | Cloud monitoring | Pull-based metrics store | Moderate (extended via add-ons) | Operational metrics |
| Apache Druid | Real-time dashboards | Distributed analytics engine | Very High | Sub-second aggregations |
| OpenTSDB | Hadoop ecosystems | HBase-backed | Very High | Basic aggregations |
| Elasticsearch | Log analytics | Distributed search engine | High | Search + time filters |
Key Factors When Choosing an Alternative
Choosing a time-series solution isn’t about selecting the “best” database—it’s about selecting the right one for your context. Developers typically evaluate:
- Write throughput requirements
- Query complexity
- Retention policies and storage costs
- Operational overhead
- Cloud-native support
- Ecosystem integration
For example, if you need advanced SQL compatibility and want minimal learning curve, a PostgreSQL-based solution may still win. But if you’re ingesting millions of time-stamped events per second and running heavy aggregation queries, a columnar engine like ClickHouse might offer substantial gains.
The Bigger Picture: A Diversifying Ecosystem
The time-series analytics landscape has matured significantly over the past decade. Instead of one dominant architecture, we now see specialization:
- Monitoring-focused systems like Prometheus
- Columnar analytics engines like ClickHouse and Druid
- Search-centric platforms like Elasticsearch
- Purpose-built time-series databases like InfluxDB and OpenTSDB
This specialization reflects how varied modern workloads have become. IoT telemetry isn’t the same as financial analytics. Log search isn’t the same as product dashboards. And infrastructure monitoring isn’t the same as historical analysis across petabytes of behavioral data.
Final Thoughts
Timescale remains a powerful and flexible tool for time-series analytics, particularly for teams that value SQL compatibility and PostgreSQL integration. However, many developers turn to alternatives when they need:
- Extreme horizontal scalability
- Columnar performance advantages
- Monitoring-native architectures
- Integrated search capabilities
- Simplified cloud-native operations
The best approach is rarely about trends—it’s about fit. By carefully evaluating data volume, query patterns, scalability needs, and team expertise, developers can choose from a diverse range of modern solutions that may outperform a PostgreSQL-based system in specific scenarios. In the expanding world of time-series analytics, flexibility and architectural alignment matter more than brand loyalty.
Comments are closed, but trackbacks and pingbacks are open.